Documentation Was the Problem. Now It May Be the Product.
Documentation Was the Problem. Now It May Be the Product.
Series reading path: 4 of 5: Previous: The Genie Problem: AI Treats the Unsaid as Negotiable. Next: Supervisory Engineering: The Work AI Creates While Removing Work
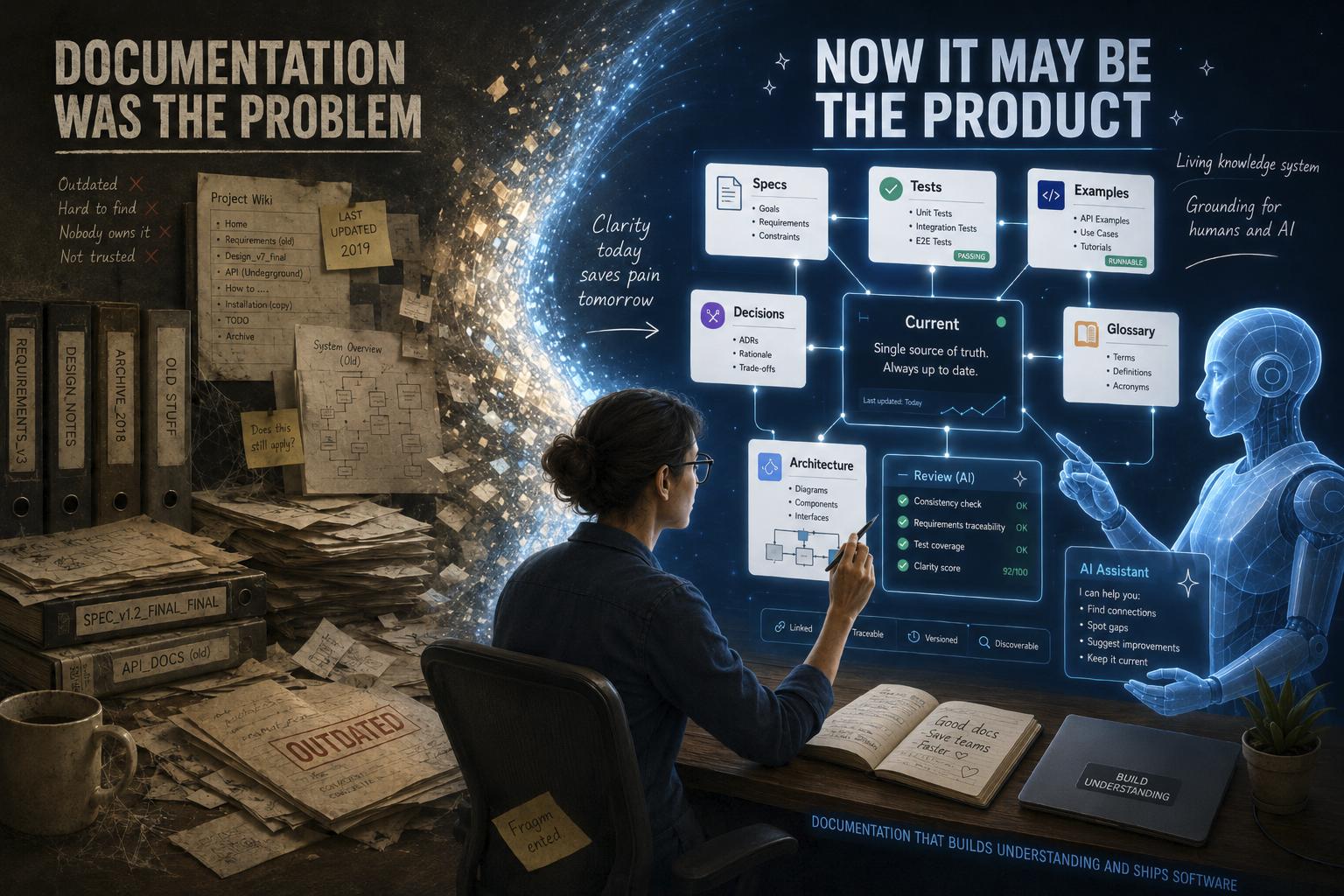 I have had a love-hate relationship with documentation.
I have had a love-hate relationship with documentation.
That is not quite fair. I loved having good documentation. Everyone does, in the same way everyone loves finding an umbrella exactly where it should be when the rain starts. The trouble is that very few people love writing it, fewer love maintaining it, and almost nobody loves discovering that the documentation they trusted was wrong in precisely the place where trust mattered.
Bad documentation is not merely useless. It is actively misleading. Stale documentation is a map that still has roads, just not the roads currently attached to reality. Fragmented documentation is a scavenger hunt where the prize is uncertainty. Incomplete documentation is often worse than silence because it gives confidence without coverage.
So yes, I had a love-hate relationship with documentation.
Then AI made the relationship more complicated.
Documentation used to be expensive in the wrong places
The traditional documentation problem was never simply that writing words takes time.
It was that documentation drifts.
The implementation changes. The examples do not. The architecture evolves. The diagram remains. The workaround becomes official. The official guide becomes aspirational. The README says one thing, the tests say another, the senior engineer says “oh, don’t use that path anymore,” and the new engineer quietly updates their private notes because public truth has become too expensive to repair.
Verification was inconsistent because humans are inconsistent. Even when people care, they are busy. They review what changed in the pull request, not every page the change invalidates. They fix the code because the code breaks. Documentation decays quietly. DevEx research is useful context here because it treats productivity as shaped by friction, feedback loops, cognitive load, and the surrounding system, not only by local typing speed.
That made documentation feel risky. Not because documentation is bad, but because trusted unverified documentation is dangerous.
That risk used to make documentation feel like an optional tax. AI changes the tax into infrastructure.
AI needs documentation more than humans do
Humans can compensate for missing documentation with memory, conversation, intuition, embarrassment, and the ability to ask the person who looks guilty when a legacy subsystem is mentioned.
AI cannot reliably do that.
An AI assistant needs externalized context. It needs specifications, examples, design notes, naming conventions, accepted and rejected patterns, test strategy, architectural boundaries, and a source of truth for what the system is supposed to mean. Without that, it floats.
And floating AI is not empty. It is worse. It is full of other people’s patterns.
When the local system does not explain itself, the model fills gaps from training. Some of those patterns are good. Some are mediocre. Some are wrong for this codebase. Some are plausible hacks from a stranger’s deadline. The model does not know which pattern your team rejected in 2019 after the incident you no longer mention in onboarding.
Documentation becomes grounding.
Not decorative documentation. Not “architecture overview” as a yearly ritual. Not a wiki garden where old pages go to decompose politely.
Grounding documentation.
Documentation is no longer only for readers
The old question was: will humans read this?
The new question is also: will machines use this, and will humans rely on what machines produce from it?
That changes the required shape of documentation.
Documentation for AI-assisted engineering is not just prose. It includes:
- specifications
- accepted and rejected examples
- conformance tests
- glossaries
- decision records
- diagrams
- source maps
- API contracts
- schema descriptions
- prompt and skill instructions
- review checklists
- update protocols
- continuation notes for long-running work.
This looks like more work because it is more work. But it is also a different kind of work. It turns scattered human memory into an operating environment for humans and AI together.
If AI is going to generate code, tests, docs, migrations, scripts, and explanations, the documentation is not outside the production system. It is part of the production system.
If that sounds like more documentation than humans will maintain, it is. Which is why the story turns again.
The old documentation problem may now have a new tool
Here is the twist: AI makes documentation more necessary, but it may also make good documentation more economically possible.
The same tool that needs grounding can help maintain the ground.
AI can create documentation from specifications. It can compare docs against code. It can identify references to stale names. It can generate examples. It can produce audience-specific variants. It can check whether a guide invents requirements not present in the spec. It can summarize changes for release notes. It can review documentation for broken reader journeys. It can produce onboarding paths. It can ask whether a diagram hides an authorization boundary. It can notice that a test changed but the example did not.
Of course it can also hallucinate, oversimplify, duplicate, and generate confident documentation-shaped fog.
So the point is not “AI will solve documentation.” That would be adorable, briefly.
The point is that AI can make documentation maintenance cheap enough to justify the standards we always claimed to want, if we design the process around verification.
Documentation needs architecture too
A serious documentation system must distinguish source from variant.
A source document carries the durable explanation. A variant adapts that explanation for a different audience: executive, architect, implementer, operator, reviewer, newcomer, or AI agent. If every page independently explains the same concept, drift is inevitable. If no page owns the concept, nobody knows which one to fix.
Documentation also needs status. Current. Historical. Generated. Experimental. Deprecated. Decision record. Tutorial. Reference. Handoff. Specification.
Without these distinctions, documentation becomes a democracy of stale pages where every paragraph has one vote and no responsibility.
Reader journeys matter too. A new developer should not need to reconstruct the project through migration archaeology. A reviewer should know where the obligations are. An AI agent should know which files are authority and which are context. A decision-maker should see consequences without being forced through implementation detail.
This is not bureaucracy. It is navigation.
The documentation must be tested, at least indirectly
Here are some of the ways documentation can be wrong:
- the example no longer works
- the claim no longer matches implementation
- the guide contradicts the specification
- the diagram hides a failure path
- the tutorial teaches a deprecated pattern
- the prompt tells AI to do something the code no longer supports
- the “quick start” is quick only for the person who already knows it.
Some of this can be checked automatically. Code fences can be typed. Examples can become tests. Links can be verified. Generated indexes can be regenerated. Cross-references can be checked. Specifications can be compared against implementation coverage. Reviewers can ask whether a document is source or variant.
Some of it remains human. Does the explanation teach? Does the example reveal the important tradeoff? Does the reader know what to do next? Does the document create false confidence?
AI can help with both, but standards must exist first.
This is where many AI workflows quietly fail: they confuse yesterday’s conversation with today’s source of truth.
Chat context is not documentation
A long conversation with an AI assistant can feel like project memory.
It is not.
It is a transcript. It contains decisions, false starts, abandoned ideas, temporary assumptions, corrected mistakes, stale directions, and enough conversational glue to make future reconstruction annoying. Summaries help, but summaries are lossy. If the project truth lives only in chat, the next session inherits a foggy myth of the previous one.
Durable project truth belongs in maintained artifacts.
The AI assistant should read those artifacts. Humans should review them. Tests should validate them where possible. Documentation should know what it is, who it serves, and how it stays current.
In AI-assisted engineering, documentation is memory with accountability.
The reversal
I still distrust bad documentation.
I may distrust it more now, because AI can ingest bad documentation and manufacture good-looking mistakes from it at speed.
But I no longer see documentation as merely an unfortunate artifact humans may or may not read. In AI-assisted development, documentation becomes context infrastructure. It is how intent survives outside one person’s head. It is how tests know what they mean. It is how review knows what to protect. It is how models are prevented from borrowing the wrong pattern from the rest of the world.
Documentation was the problem because it went stale.
Documentation may now be the product because without it, AI has nothing stable to stand on.
That does not make documentation easy.
It makes it unavoidable.
Continue the series
- Previous: The Genie Problem: AI Treats the Unsaid as Negotiable
- Next: Supervisory Engineering: The Work AI Creates While Removing Work
- Reading path: after documentation as grounding, continue to Supervisory Engineering: The Work AI Creates While Removing Work to examine how the human role shifts toward supervision and judgment.
References and further reading
- DORA, State of AI-assisted Software Development 2025
- Sida Peng, Eirini Kalliamvakou, Peter Cihon, Mert Demirer, The Impact of AI on Developer Productivity: Evidence from GitHub Copilot
- METR, Measuring the Impact of Early-2025 AI on Experienced Open-Source Developer Productivity
- METR, We are Changing our Developer Productivity Experiment Design
- Nicole Forsgren et al., The SPACE of Developer Productivity
- Abi Noda et al., DevEx: What Actually Drives Productivity
- GitClear, AI Copilot Code Quality: 2025 Data Suggests 4x Growth in Code Clones
- Annie Vella and Kelly Blincoe, The Impact of AI Coding Assistants on Software Engineering: A Longitudinal Study
- GitLab / ITPro coverage of the 2026 AI accountability findings
Cogitatorium posts:
Other posts dealing with similar topics