REST API (1): What?
Are you using or building a REST API? Why? Which benefits are you getting? Are you sure? Did you check, compare against alternatives or just assume it is “accepted knowledge” for REST APIs? That said, is that API actually a REST API? How do you know? Did you follow some standard, specification, or definition or is “REST” just a word that was nearby? What is a “REST API”?
Many of you may find these questions funny, because either you know what you’re doing or because “you know what you’re doing”. Does it matter? Well, think what effect would being wrong have? Could that negatively affect making decisions due to incorrectly assumed benefits and ignored shortcomings? Could those affect effort, outcomes, and bottom line? I think there is only one answer: it does matter. Let’s start thinking about this together.
Where’s the definition?
To avoid implying my own perspective here, we’ll begin with a snippet from Wikipedia taken on October 14th, 2023:
REST (Representational state transfer) is a software architectural style that was created to guide the design and development of the architecture for the World Wide Web. REST defines a set of constraints for how the architecture of an Internet-scale distributed hypermedia system, such as the Web, should behave. The REST architectural style emphasises the scalability of interactions between components, uniform interfaces, independent deployment of components, and the creation of a layered architecture to facilitate caching of components to reduce user-perceived latency, enforce security, and encapsulate legacy systems.[1] REST has been employed throughout the software industry to create stateless, reliable Web-based applications. An application that obeys the REST constraints may be informally described as RESTful, although this term is more commonly associated with the design of HTTP-based APIs and what are widely considered best practices regarding the “verbs” (HTTP methods) a resource responds to while having little to do with REST as originally formulated - and is often even at odds with the concept.[2]
And, soon after that:
The term representational state transfer was introduced and defined in 2000 by computer scientist Roy Fielding in his doctoral dissertation. It means that a server will respond with the representation of a resource (today, it will most often be an HTML, XML or JSON document) and that resource will contain hypermedia links that can be followed to make the state of the system change. Any such request will in turn receive the representation of a resource, and so on. We’re getting somewhere. Let’s go to that source, the doctoral dissertation of Mr Fielding. I do recommend reading it. REST is defined in Chapter 5 (pages 76-105), with prior and subsequent chapters giving more context and evaluation. Here are the links I found:
Here are some relevant excerpts (citations) from that document that describe what REST is meant to be, without going into rationales and what it is not.
-
“REST is a hybrid style derived from several of the network-based architectural styles described in Chapter 3 and combined with additional constraints that define a uniform connector interface.”
-
(5.1.2) “The first constraints added to our hybrid style are those of the client-server architectural style (Figure 5-2), described in Section 3.4.1.”
-
(5.1.3) “communication must be stateless in nature” and (5.2.2) “All REST interactions are stateless. That is, each request contains all of the information necessary for a connector to understand the request, independent of any requests that may have preceded it.”
-
(5.1.4) “In order to improve network efficiency, we add cache constraints to form the client-cache-stateless-server style of Section 3.4.4 (Figure 5-4). Cache constraints require that the data within a response to a request be implicitly or explicitly labeled as cacheable or noncacheable.”
-
(5.1.5) “The central feature that distinguishes the REST architectural style from other network-based styles is its emphasis on a uniform interface between components (Figure 5-6).” […] “The REST interface is designed to be efficient for largegrain hypermedia data transfer, optimizing for the common case of the Web, but resulting in an interface that is not optimal for other forms of architectural interaction.”
-
(5.1.6) “Within REST, intermediary components can actively transform the content of messages because the messages are self-descriptive and their semantics are visible to intermediaries.”
-
(5.1.7) “REST allows client functionality to be extended by downloading and executing code in the form of applets or scripts.”
-
(5.2.1) “Unlike the distributed object style [31], where all data is encapsulated within and hidden by the processing components, the nature and state of an architecture’s data elements is a key aspect of REST.”
-
(5.2.1.1) “The key abstraction of information in REST is a resource.” […] “A resource is a conceptual mapping to a set of entities, not the entity that corresponds to the mapping at any particular point in time.”
-
(5.2.1.2: Representations) “REST components perform actions on a resource by using a representation to capture the current or intended state of that resource and transferring that representation between components.” … “The data format of a representation is known as a media type [48].” … “Composite media types can be used to enclose multiple representations in a single message.”
-
(5.5: Summary) “This chapter introduced the Representational State Transfer (REST) architectural style…”
Did it evolve?
Everything evolves but not necessarily in a single, consistent way or the way the author intended. Just ask the author - Mr. Fielding. I strongly recommend reading his own notes on the subject, they also explain what REST API was not meant to be):
I am getting frustrated by the number of people calling any HTTP-based interface a REST API. Today’s example is the […] That is RPC. It screams RPC. There is so much coupling on display that it should be given an X rating.
20 Oct 2008 (Direct link) (Web Archive)
Do you know of a standards organization that defines REST for everyone? As of Oct 2023 I am not aware of one, only a few that try to help, independently. Please, do let me know if there is one and why is it The One. Here are a few that I am aware of:
-
Mr. Fielding’s dissertation noted earlier
-
restfulapi.net
-
restapitutorial.com
-
restcookbook.com
-
Wikipedia
-
service-architecture.com
Those above generally stay more or less true to Mr Fielding’s writings but have a look at OData.org (Web Archive), for example. It states:
OData - the best way to REST
An open protocol to allow the creation and consumption of queryable and interoperable RESTful APIs in a simple and standard way.
OData (Open Data Protocol) is an ISO/IEC approved, OASIS standard that defines a set of best practices for building and consuming RESTful APIs.
Surely that must be better! It is a standard and clearly states that it is the best. Why is there a need to point out the differences? For example:
-
DreamFactory Blog: OData vs REST: What You Need to Know (Web Archive)
-
Odata and REST APIs - A Comparison by Rajeev Gupta [(Web Archive)][https://dbsyncseo.medium.com/odata-and-rest-apis-a-comparison-ef4408c4f5e2]
Out of curiosity, here’s what ChatGPT says (at the time of writing, no, you don’t need to trust it):
OData is a protocol that standardizes the way in which REST APIs are built and consumed. It does adhere to many REST principles, but whether it conforms to all of Fielding’s constraints is a matter of interpretation and debate. Some argue that OData does not fully embrace the hypermedia constraint, a key aspect of REST according to Fielding’s dissertation. OData does provide a standardized way of accessing data through RESTful APIs but may not align perfectly with all of Fielding’s constraints.
Then there are statements like the following:
I’ve read several articles about REST, even a bit of the original paper. But I still have quite a vague idea about what it is. I’m beginning to think that nobody knows, that it’s simply a very poorly defined concept. Like Web 2.0, everyone talked about it but nobody could give a clear definition. Thoughts?
Hacker News: Ask HN: What is REST exactly? Feb 8, 2014 (Web Archive)
Entire articles attempting to address that exact question, such as, well, this one, or the following (some also citing it):
Roy Fielding’s Misappropriated REST Dissertation
RESTful APIs are everywhere. This is funny, because how many people really know what “RESTful” is supposed to mean?
or:
50 Shades of REST - How the Constraints of REST Will Set You Free
Roy Fielding’s original doctorial thesis outlined six major constraints that you need to fulfil to be RESTful. Dr Fielding himself has stated that unless you implement ALL of these constraints, you have no right to call your interface RESTful. Harsh? Maybe Roy is trying to teach us and maybe these six constraints are his pleasure room?
Jeff Watkin’s April 22, 2018 post on LinkedIn (Web Archive)
Can REST APIs support GraphQL? They can if you believe Informatica KB 000108579. It mentions the ability to “consume any REST API which supports GraphQL” right at the top.
What’s going on here?
There is an obvious disagreement on what REST is or should be, whether the constraints that can “set you free” are needed or not to benefit from the approach. Also, when we describe our APIs to others, what should we say to make sure that we do so clearly? For example, if we do say that “we’re offering” a, for example, OData, SOAP, gRPC, GraphQL, CORBA, RMI or DCOM API we are setting some clear expectations. What expectations are we setting when we use the term “REST” that aren’t included in just saying that it is an HTTP-based API?
-
Are we implying some standard “media” formats? Based on XML, JSON, CSV, binary, other? I don’t think so. And yet, many do imply JSON, most of the time.
-
Are we implying the ability to leverage caches? How could that work if authentication is required and authorization yields different representations for different users?
-
Are we implying a uniform interface? For example, “manipulation of resources through representations” and using the “intended state of that resource and transferring that representation between components”? I don’t think so. That may seem like a noble goal but is also often a can of worms. What happens when you try to address the following questions:
-
How does one manipulate multiple resources together?
-
What happens when a client isn’t permitted to see the entire state, so it can’t manipulate it or communicate it back either?
-
What happens when the intended state is the same as current but a specific workflow, transition is needed?
-
When a client sends a manipulated “intended” state, is the part it didn’t change intentional and required or irrelevant to the manipulation? Can the server somehow reconcile, merge multiple such changes together, make sure the last one wins or detect such conflicts?
-
How are the clients meant to manipulate the parts of the state representation that they don’t understand as it came after their code was developed?
-
-
Are we implying “client-server separation of concerns”? What is that? For example, in its section “1.2. Client-Server”, restfulapi.net [Web Archive] says “By separating the user interface concerns (client) from the data storage concerns (server)…” but are all clients UIs and all servers just data storage appliances? Haven’t servers evolved to do more? Are all the clients supposed to act the same? Say mobile and web?
-
Are we implying working with resources, not just “endpoints”? Heck, that word “endpoints” just appeared for the first time here, yet is frequently used together with REST APIs. What is it, why is it there and does it even belong?
-
Are we implying some sort of documentation or specification? Hint: It isn’t OpenAPI, it clearly states “The OpenAPI Specification (OAS) defines a standard, language-agnostic interface to HTTP APIs” - i.e. not specifically REST.
Are we implying anything, really? If not, why would we say “REST” at all? If we did, are those implications the same for everyone? And what hoops did we jump through to make them true? Were they worth it? Can we say that we’re going with the flow as the approach is popular? How can we say that if we can’t agree on what it is? Maybe it’s just the word, “REST”, that is popular?
Can we make any sense of this?
I think that knowing the implications and being able to make choices is more important than knowing the name, as long as we’re aware of the naming issue. As it all originated with Mr Fielding and there is a less-than-perfect “agreement” outside his work, I will suggest that we take his work as the definitive specification of REST. To avoid inadvertently spreading additional misinformation I choose to not try to explain it or help with it. I fully accept that my own understanding of it may be flawed.
What I am going to do instead is offer my own thoughts that I had at roughly the same time and along roughly the same lines as Mr. Fielding. It was the dawn of the HTTP APIs, Internet-wide distributed processing, and a fresh wave of thinking of the responsibility division. I had to design a few new APIs and was faced with different kinds of beauty in different approaches. A simple way to understand my thoughts is to begin thinking of computer systems (or services they expose) as huge (but still finite) state machines. What are state machines? Well, they are machines that transition from one state to another when reacting to input. There are many states (more about that later) and each could have a nontrivially large representation.
It was common to imply that operating those state machines meant indicating the transitions and the machine would, then, arrive at the appropriate states at the end of those transitions. An example machine could have simple integers as states and for each state, it may support two transitions: “double” and “decrement”, allowing us to navigate between states by, well, doubling and decrementing the current states. This is in contrast to observing the states - just a simple number. It may also be impossible to arrive from one state to another - say from a negative to a positive number. That may feel and, in fact, be a “miss”. This brought in a desire to explore the possibility of supporting a hyperspace/wormhole feature - the ability to directly jump to the specified state.
Let’s think of “states” as cities and transitions as driving between them. Take the following map as an example:
Our map of the world
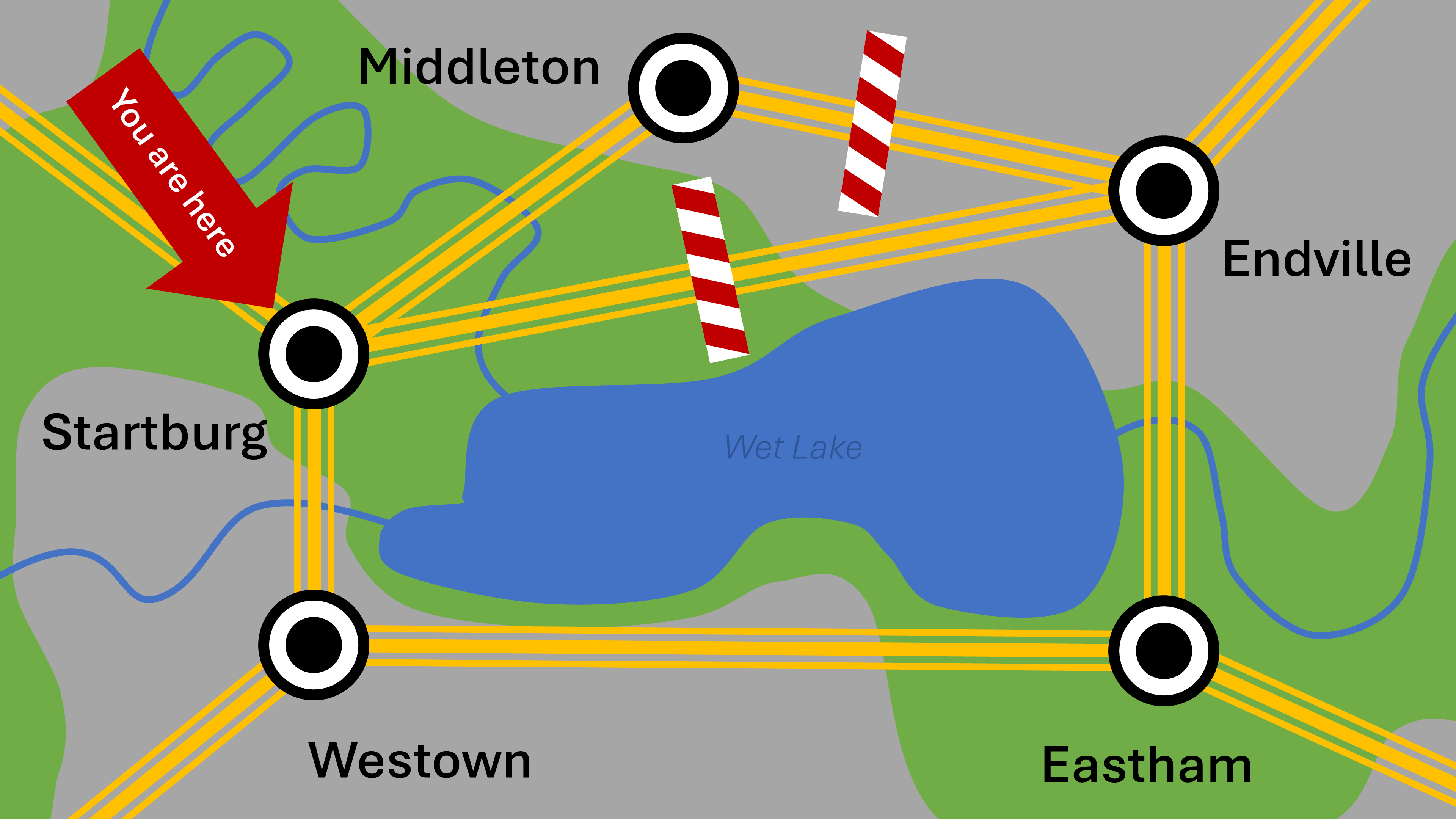 We see a number of cities, Startburg, Middleton, Endville, Westown and Eastham, interconnected by highways. Not every city is directly connected with every other one. Even when direct highways exist they may be closed down, for whatever reason - maybe they require special authorization, are under construction, or may be shut down due to an accident. In our case we can’t travel between Endville and either Startburg or Middleton.
We see a number of cities, Startburg, Middleton, Endville, Westown and Eastham, interconnected by highways. Not every city is directly connected with every other one. Even when direct highways exist they may be closed down, for whatever reason - maybe they require special authorization, are under construction, or may be shut down due to an accident. In our case we can’t travel between Endville and either Startburg or Middleton.
Our user’s story begins in Startburg. The user wants to reach Endville. How should the user express that desire to our fictitious API? There are at least two distinct approaches.
Approach 1: Describe Transitions
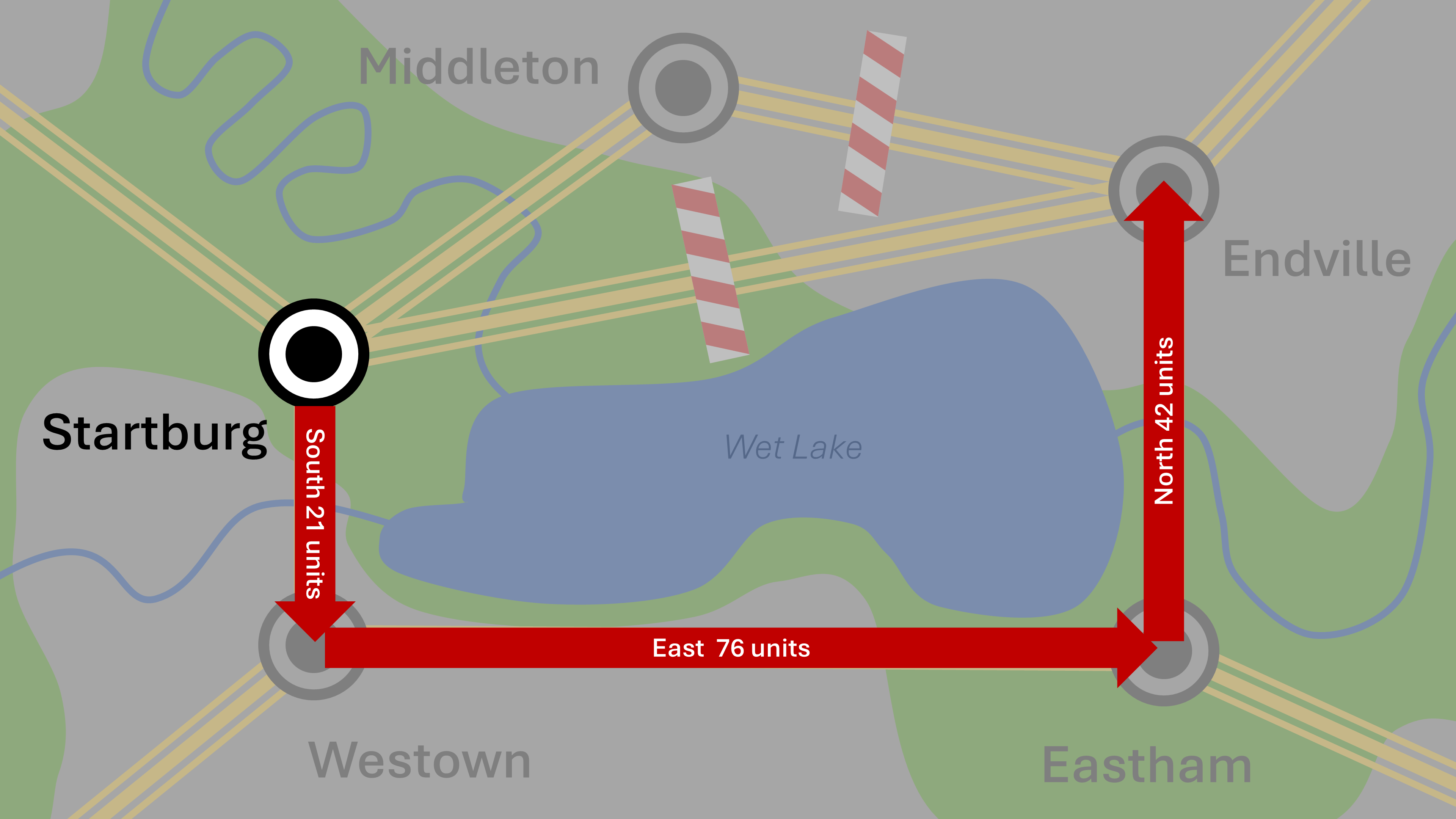 Surroundings don’t matter. The client isn’t telling the server what the desired destination is either. All that is irrelevant. Instead, the client is giving clear travel directions, in this case 21 (distance) units south, 76 units east, then 42 units north. These three steps can be bound into a batch.
Surroundings don’t matter. The client isn’t telling the server what the desired destination is either. All that is irrelevant. Instead, the client is giving clear travel directions, in this case 21 (distance) units south, 76 units east, then 42 units north. These three steps can be bound into a batch.
The server is responsible for validating and following the directions exactly as stated. I went to the extreme here to illustrate a point. A more common scenario would be “take highway such-and-such until exit such-and-such” instead.
Approach 2: Specify the desired state
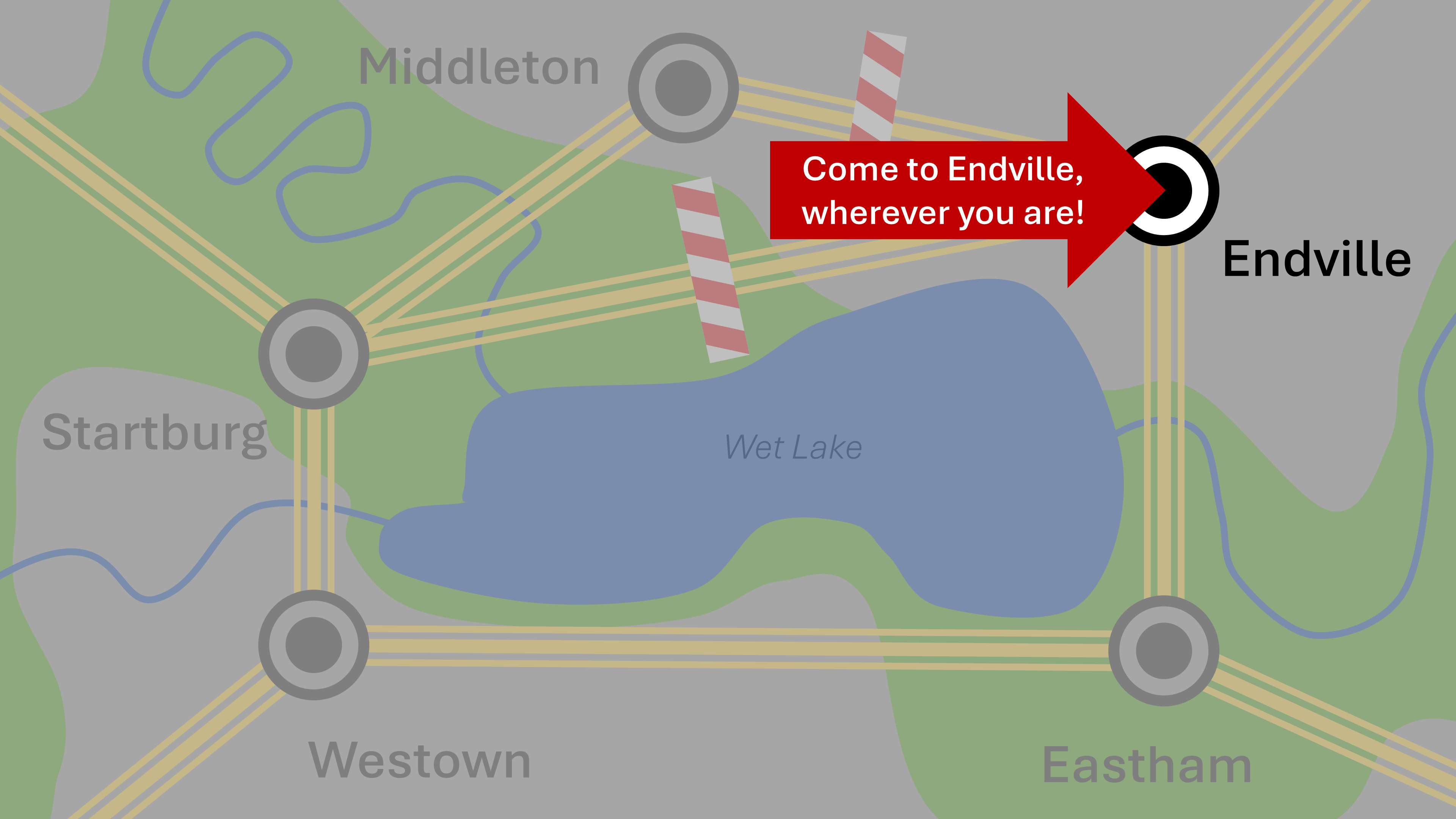 The other approach is to simply state “go to Endville”, not at all caring or indicating how to accomplish that. Figuring that part out is the server’s job. The server also has to validate that the destination is valid (exists as a possibility) and is that it is reachable. This “reachability” isn’t about unimplemented server features but whether the user is permitted (authorized) to reach the desired state. Additionally, business logic and laws of the system and nature may prevent some of these “jumps” as well. For example, if a physical, real-world entity is destroyed, it cannot be brought back.
The other approach is to simply state “go to Endville”, not at all caring or indicating how to accomplish that. Figuring that part out is the server’s job. The server also has to validate that the destination is valid (exists as a possibility) and is that it is reachable. This “reachability” isn’t about unimplemented server features but whether the user is permitted (authorized) to reach the desired state. Additionally, business logic and laws of the system and nature may prevent some of these “jumps” as well. For example, if a physical, real-world entity is destroyed, it cannot be brought back.
Note that different paths may (or not) have different side-effects, which may be of concern to the user. How should the server choose the right path in that case?
Here are some additional notes and observations:
-
One approach describes what needs to be done, and another what is the end goal.
-
Technically both can be done as multiple steps. For example, with approach #2 the client could issue three separate requests: to get to Westown first, then Eastham, then Endville.
-
It may seem like approach #1 requires more interactions but do realize that so may approach #2 if the server needs additional information for non-trivial routes. Generally speaking the number of steps may be equivalent as transitions may not be as limited as shown on the map. “Fly to Endville” could be a valid transition.
-
Both seem to accomplish the same goal in the end.
Until next time
I will leave you here with a final set of questions to think about on your own until the next post:
-
Which approach do you think REST is closer to?
-
What is transferred in the approach #2 from the client to the server? Would the client send just the “name” of the desired destination? Would the client transfer a representation of the state of the entire system (including all actors, people, vehicles, buildings, financials, weather, etc) or just a subset? What do you think REST would do?
-
Who (client, server) is in control of what, what are they responsible for? How does the client “know” what changes are acceptable, and which states are permitted? What happens if we add new components to the state, such as altitude or a more accurate location?
-
Which approach is more generic, if any? Can one emulate all aspects of the other?
-
What happens in a concurrent multiuser situation?
-
Which approach seems to model your case better?
Next…
Continue to part 2 to think about how to carve the state(s).
Alternatively you may head to GraphQL: What it is not! to see how REST isn’t alone in the world of misconceptions.
Other posts dealing with similar topics