Authorization: A Thought Scaffold
 How confident are you in your system’s security? Are you certain it’s solid, or just fairly sure you’ve probably missed something? Have you checked every box you’ve come across, only to find new ones constantly appearing?
How confident are you in your system’s security? Are you certain it’s solid, or just fairly sure you’ve probably missed something? Have you checked every box you’ve come across, only to find new ones constantly appearing?
Let’s take a step back and explore the different dimensions of security - not to find definitive answers, but to build a framework for thinking more critically about it. Expect mostly questions, not my personal conclusions. If I were to generalize those, I’d have to play it safe and suggest what some might call “overkill”. I prefer not to give recommendations without context.
You have the context. I have the questions. Let’s go!
It’s More About What You Don’t Do Than What You Do
Nothing exists in complete isolation, and that includes whatever you secure. To be useful, your “secured piece” must interact with its surroundings. Those surroundings, in turn, interact with others, creating a chain of dependencies. So, what are you doing about this?
- You’re not concerned. You’re doing nothing because it doesn’t bother you. In that case, why are you reading this?
- You’re an absolute control freak. Nothing ever leaves your control - not even users. The entire system is locked down, existing solely for its own sake. Nobody on the outside knows anything about it.
- Somewhere in between. You do your best to stay ahead of potential threats but accept that some level of risk is inevitable.
Unless you fall into the first category, let’s explore various aspects and levels of security considerations. Some follow a natural progression, while others overlap.
Route sensitivity
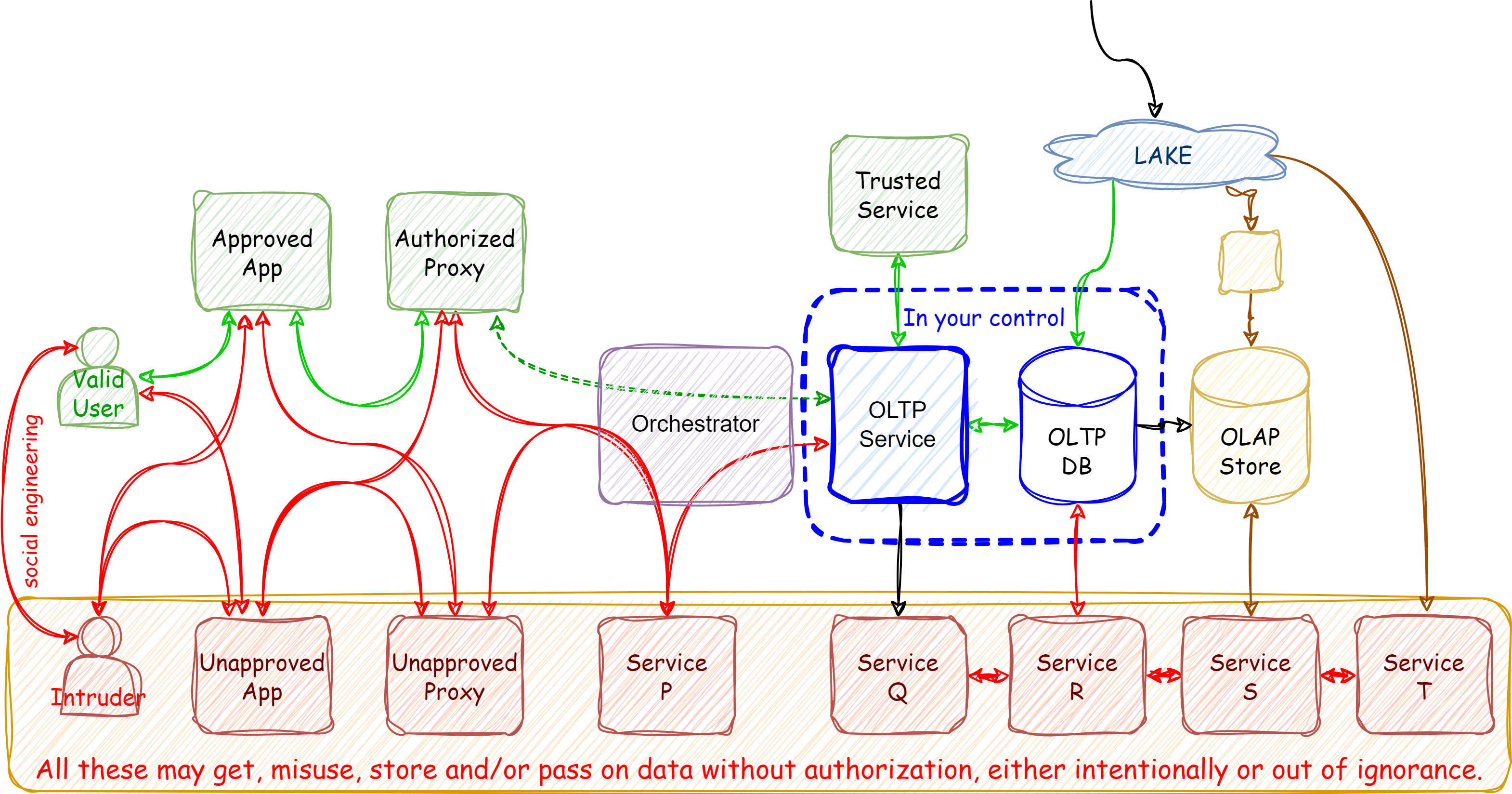
Take a look at this diagram. Suppose you are primarily responsible for the components marked as within your control. This includes handling incoming data and validating inputs. If the data entrusted to you is misused, you will be held accountable.
As a baseline, assume that anything outside the dashed blue box is beyond your control. In fact, assume that none of the other “boxes” are well-managed or necessarily trustworthy. They may not follow your security practices and could even be compromised.
Would you trust them to access your data? What about having visibility into your input data? Is it acceptable for data in your care to pass through these untrusted boxes on its way between your end users and the systems you control?
How do you ensure trust or prevent data from flowing where it shouldn’t? Do you:
- Cut off communication entirely?
- Demand adherence to your security expectations?
- Ignore it because it’s not your problem?
Authentication
Does it matter who you’re communicating with? Is authentication enough, or should access vary depending on the entity?
Who do you authenticate? Do you focus solely on the end user, or do you also authenticate all the components between your systems and the user? If you don’t, how do you trust the route?
Is end-user authentication transferable? Could a stolen authentication response allow someone else to impersonate the legitimate user?
These are just a few of the many questions surrounding authentication.
Some of these challenges can be mitigated by placing an authentication wrapper around an existing service. Such wrappers exist, sometimes in the form of BFFs (Backend for Frontend), and they can be quite helpful. However, as we dig deeper, we’ll see that they don’t solve everything.
Data Access Specificity
What level of detail is needed when differentiating users in terms of the access they have?
Here are the possibilities I’ve encountered so far:
-
Service level: Full access to the entire service (API) is either granted or not at all.
-
Entity type level: Full access to specific endpoints or all instances (and properties) of certain entity types, or none at all.
-
Entity instance level: Full access to specific instances of entities or resources (all properties, values, etc.), or none at all.
-
Property type level: Full access to all values of specific types of properties (e.g., personally identifiable information) of all accessible entities or resources, or none at all.
-
Property instance level: Full access to all values of instances of properties specific to instances of entities. Access may be granted on some entities but not others, even if the entity and property type are both accessible. This is often the case when customers’ explicit approval is required for support agents to access their data.
-
Value level: Even if access is granted to a property, some values within it may need to be hidden, indicating that the property has fewer visible values, or none at all. For example, certain enumerated interests or responsibilities may be visible, while others remain hidden. This is often the case with link properties referencing other controlled entities.
-
Value detail level: Different parts of a complex or structured value may be accessible or not. For example, some users may only see the country, region, and perhaps the city of an address, while others may also have access to postal codes and detailed street addresses.
How far do you need to go? Are you sure?
Are you planning to implement authorization directly within your service, or will you shield it and secure it through an external wrapper? If you opt for the latter, think about how that wrapper will access all the necessary data to make its access control decisions.
You may have noticed a mention of “link” properties. Even if you don’t require anything more granular than entity instance-level authorization, linking to controlled entities brings you closer to that level, often without you realizing it. Suddenly, you’ll need to hide individual values if they reference entities that aren’t meant to be visible. You might skip levels (4) and (5) and jump straight to (6) or even (7).
This is where things get even more interesting. When do you enforce link authorization? Is it acceptable to leak an ID or instance of the target entity if the relation or existence of the target entity shouldn’t be known by the end user? Both cases leak data to some degree. Would you be comfortable if others knew how many times you visited certain types of medical doctors, even if they couldn’t see the details of those visits? Fun, isn’t it?
Action Specificity
Sometimes it’s not just about the data being accessed, but what is done with it. Take a property, like a “status”, where viewing and even modifying it may be allowed, but not for every possible value. Some state transitions may require additional scrutiny and authorization. These transitions may not depend solely on the destination state. After all, if the sensitive state is already the current one, switching to it isn’t a transition at all. In other words, authorizing specific transitions requires knowledge of both the current and intended state - or it may involve explicitly authorizing the transition, which is determined by other code.
It doesn’t stop there. This was about modifying things. But what about simple, read-only actions? Suppose your detailed contact information is stored in the system. You submitted it yourself because you needed to be notified of things that are important to you, and you clearly agreed to that. You should be able to access that information to keep it up to date. Those responsible for sending you those important notifications should also be able to access it. You opted out of promotional notifications, but it’s the same people and systems handling it all. Moreover, this data may travel through intermediate systems and might even leave your continent for a time. Is that OK? Who or what is responsible for ensuring your contact information isn’t abused or routed inappropriately? Who is responsible for saying, “Sure, using this for approved purposes is fine, but I won’t allow marketing or data to leave Europe”?
Will you:
- Rely on the goodness of everyone’s hearts and the ultimate reliability of human brains, trusting that they’ll always honor the agreements and never miss a detail?
- Trust no one, keep the data to yourself, and expose every separate “purpose” as an independently authorizable action?
- Build trust with some external parties, expecting them to honor your contracts, including not passing information to anyone or any system you haven’t approved - no unapproved proxies, loggers, or other unapproved services, even if they’re handled by the same orchestrator?
Which of these options would stand up in court to defend your organization? And how much effort does each option require?
Some more fun
There are cases where a user is authorized to both access a collection of data and perform actions, but the finer details interact in interesting ways. Imagine a document management system that, among other things, keeps track of the authors of those documents. This system is used by an institution with extreme security needs. Even if you’re allowed to view a document, you may not be permitted to know about the existence of some employees - their identities must not only be hidden, but you shouldn’t even be able to discover that they exist in the first place. Let’s say one of these secret employees goes by the name “James Bond”.
Some of these secret people may have contributed to writing some of the documents you can access. If you list the authors of those documents, the value-level security we discussed earlier can handle excluding references to them - meaning they won’t appear on the list. So far, so good. But now, think about what happens when a request is made for one of the following instead of the list of authors:
-
Derived Data: The number of authors. If two out of five authors need to be hidden from you, the answer must be “3”. Note that this logic can only be applied where the complete data exists. You can’t implement a wrapper that turns a simple “5” into a “3” without having full access to the data and performing the calculation.
-
Positive Criteria: Documents with a specific ID or name that have at least one author named “James Bond”. The ideal system should exclude the original document from the results, as including it could lead to fishing and inadvertently reveal the existence of people who shouldn’t be known.
-
Derivative Criteria: Documents with a specific ID or name and more than three authors. The outcome here would be similar to the previous case.
-
Negative Criteria: Documents not written by “James Bond”. Since this person is supposed to be nonexistent, all documents should be treated as matches. This becomes an active lie, not just filtering, and cannot be handled by filtering proxies alone.
These were simple, read-only cases. They can get more complex. And they don’t have to be read-only. Consider how the system should handle the following situations without knowing that certain authors were excluded:
- Replacing the list of authors with another
- Adding new authors in order of how much they contributed
- Reordering the list of authors
Bonus: Asynchronicity and Broadcasts
Asynchronous processing plays a crucial role in software systems. I won’t go into too much detail, but simply put, it refers to deferred processing that happens some nontrivial, possibly significant, time after the triggering event. This brings up a somewhat “philosophical” question: When is authorization due?
-
When triggered only: You’re okay if processing executes even after access has been removed at the trigger time.
-
At processing time only: You’re okay giving the initiators a possibly wrong impression.
-
Both when triggered and at processing: You’re okay with changing your mind midway.
Keep in mind that some asynchronous processing is repetitive, not a “single shot”. A good example of this is in events or notifications meant to keep recipients informed about ongoing activities. These add more steps to the process. The first part culminates with sending the notification, and the second involves the recipient(s) consuming it. Is that asynchronous with respect to sending the notification? Or is it simply a “poke” expecting a “pull”? “Hey! I’ve got news - call me back when you can to get them”.
Do you eliminate the need for the callback by including the details in the notification itself? If so, you’ll need to authorize the details before sending them. How many recipients are there? Do you even know who they are? Are you in control? Do you only include details that everyone on the list can see? And, if you do that, does it not risk giving the wrong data to those who could see more?
Instead of the Conclusion
I apologize if this has caused any headaches - I truly sympathize, as I’ve been through the same challenges. There is indeed a light at the end of the tunnel, but from my experience, the tunnel itself is filled with half-baked solutions from those who ignored the warning signs along the way. Many REST APIs seem to suffer from the assumption that simply authorizing the HTTP method + endpoint combination, perhaps with filtering of resource entities at the top level, is enough. Too often, little or no thought is given to the security of links, derived data, actions, and criteria-driven phishing. Be prepared to tackle these challenges head-on.
Next…
Continue to my post about how to recognize inappropriate activity or go back to the series about RESTful or GraphQL APIs.
Other posts dealing with similar topics